第2章: 使用ArchR推断Doublet
单细胞数据分析中的一个重要问题就是”doublet”对分析的影响。”doublet”指的是单个液滴(droplet)捕获了一个条形码珠(barcode bead)和多个细胞核。这会导致原本来自于多个细胞的read结果被当成一个细胞,结果原来两个细胞被平均成一个细胞。我们在这一章中将会介绍如何使用计算的方法鉴定并过滤doublet。
2.1 ArchR是如何鉴定doublet
几乎所有平台得到的单细胞数据都或多或少的存在doublet。所谓的doublet就是一个液滴中混入了多个细胞的细胞核,导致原本的多个细胞被认为是一个细胞。在10X Genomics平台,doublets的细胞比例和一次反应中的细胞数有关,细胞越多,doublet也就越多。不过即便你按照标准流程,也依旧会存在一定比例的doublet,而只要有5%的doublet数据,就会对后续的聚类分析造成影响,尤其是后续的发育/谱系分析。因为doublet看起来像是两类细胞的中间状态,但是当你不知道这是doublet造成的假象时,你就会得到错误的结论。
为了预测哪些细胞才是真的doublet,我们通过对不同细胞进行组合得到模拟的doublet(in silico doublets),然后将这些模拟的doublet和原来的细胞一同投影到UMAP,接着确定和它们最近的细胞。通过不断地迭代对该步骤,我们就可以找到数据中那些与模拟doublet信号最接近的细胞。这些细胞就是潜在的doublet。
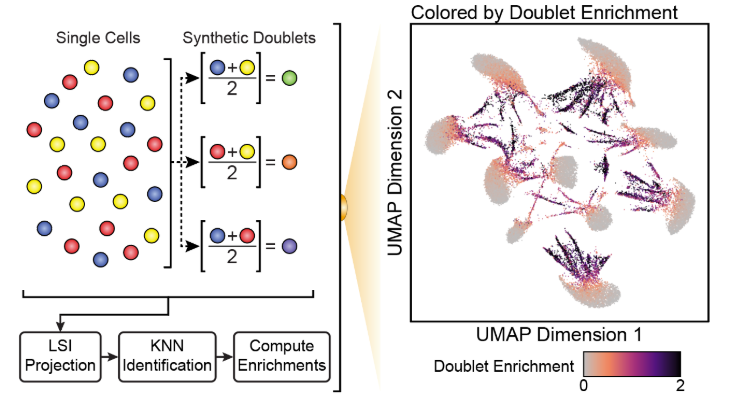
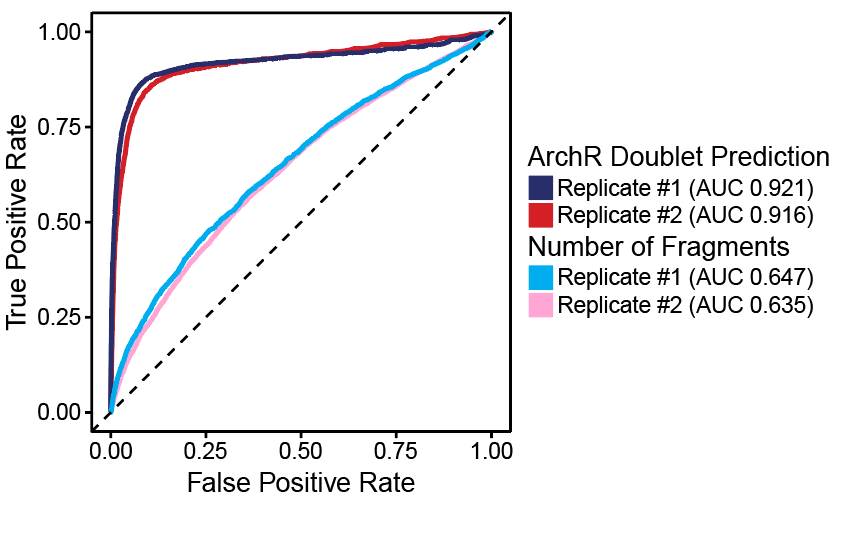
为了开发ArchR的doublet鉴定算法并验证它的可靠性,我们将10个不同类型的细胞进行混样测序。在没有doublet的情况下,我们的scATAC-seq数据最终应该有10个不同的细胞类型。但是当我们故意在10X Genomics scATAC-seq试剂中加入过量的细胞(25,000/per reaction), 我们会得到许多doublet。我们使用demuxlet根据一个细胞里是否包括两种不同细胞的基因型来判断该细胞是否是doublet。
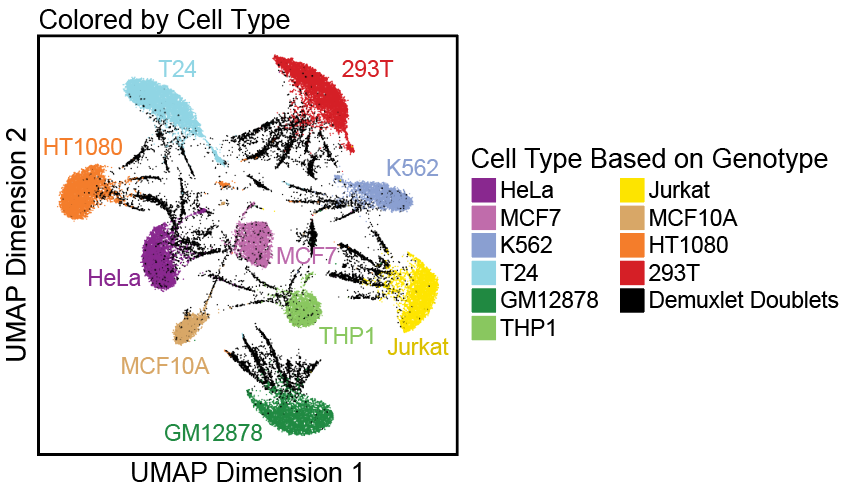
如上图所示,我们的真实结果(ground truth)被预测的doublet覆盖。ROC曲线中的AUC(area under the curve) > 0.90(见注1)
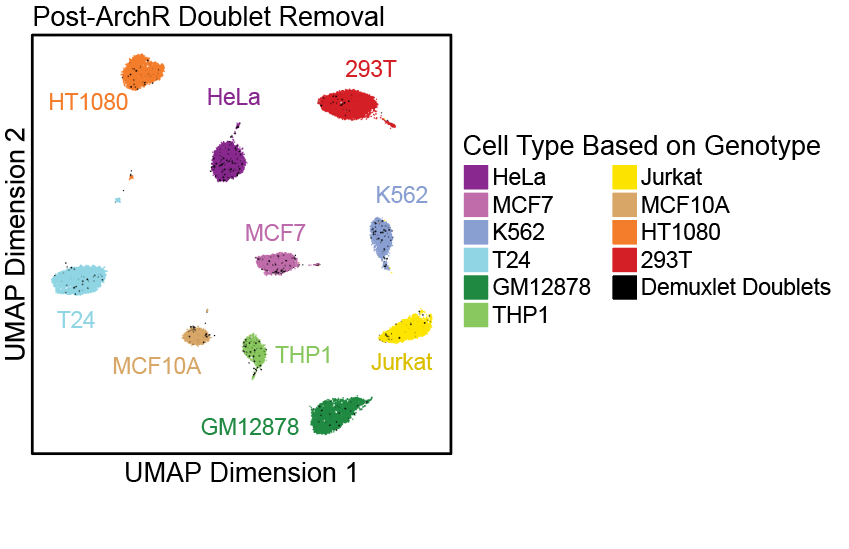
ArchR通过计算的方法移除这些doublets后,我们数据整体结构有了明显的变化,符合预期,也就是有10个不同的细胞类型。
注1: ROC曲线全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的曲线。AUC就是衡量学习器优劣的一种性能指标,AUC越接近于1.0,表示检测方法真实性越高, 等于0.5表示真实性越低
2.2 使用ArchR推断scATAC-seq doublets
ArchR默认使用ArchR手稿中的doublet参数。我们建议用户检查移除doublet前后的数据变化,理解移除doulet对细胞的影响,根据结果对已有的参数进行调整,而不是生搬硬我们的参数设置。我们也会展示一些
我们使用ArchR的addDoubleScores()函数来移除doublet。对于教程中使用的数据,每个样本大约需要2到5分钟时间进行处理,最后每个细胞的doublet得分会添加到Arrow文件中。 你可以使用?addDoubletScores了解该函数的每个参数的意义。
1 | doubScores <- addDoubletScores( |
我们以其中一个样本运行过程的输出日志信息进行介绍,这里的R^2用于描述样本中的细胞异质性,如果该数值非常小(例如小于0.9),说明该样本的细胞都非常相似。那么使用模拟的方法去鉴定doublet就不太合适了。这个很好理解,如果所有细胞都表达一个基因,并且表达量是1,那么你模拟的doublet也会只有一个细胞,且表达量是均值1,结果就是所有细胞都是doublet。在这种情况下,我们推荐跳过doublet预测这一步。或者你可以尝试设置knnMethod = "LSI",force = TRUE,在LSI子空间中进行投影。(相当于提高分辨率)。无论如何,你都需要手动检查结果,确保运行过程符合预期。
1 | ## If there is an issue, please report to github with logFile! |
这里的R^2大于0.9,表示细胞存在异质性。
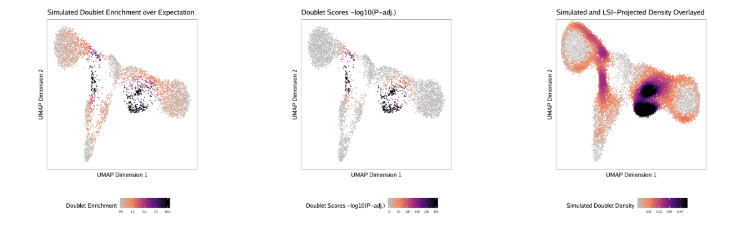
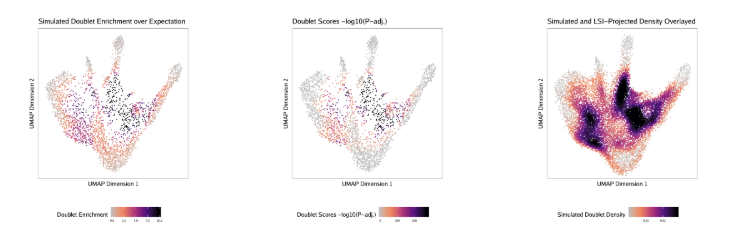
addDoubletScores在计算doublet得分的时候,还会在”QualityControl”中为每个样本生成三张图(一个样本一个PDF)
- Doublet Enrichments: 假设doublet符合均匀分布,那么每个细胞附近的模拟doublet数目都差不多。如果一个细胞附近相对于其他细胞有更多的doublet, 就认为它富集了doublet
- Doublet Score: 基于均匀分布假设,计算doublet富集显著性,以
-log10(binomial adjusted p-value)进行展示。我们更推荐根据doublet enrichment鉴定doublet。 - Doublet Density: 模拟的duoblet在二维空间的投影,我们可以直观的了解我们模拟的doublet的分布情况。