当我们通过一些流程化工具对一个基因组进行注释之后,最终得到的注释结果(通常是GFF文件)或多或少存在一些注释错误,需要通过人工校正。
我们的目标是安装一个能够在自己服务器使用的Apollo用于人工注释,以下的操作都需要用到管理员权限。
Docker
既然都得用到管理员权限,我们优先使用Docker的方法进行安装。
第一步: 获取Docker镜像
1 | docker pull gmod/apollo |
第二步: 启动
1 | docker run -d -it --privileged --rm -p 9999:8080 -v /tmp/apollo_data gmod/apollo |
最后就可以打开网页,输入服务器IP:9999即可打开网页
默认的账号admin@local.host,密码是password
常规方法
第一步: 安装必须的依赖环境
1 | sudo yum install zlib zlib-dev expat-dev libpng-dev libgd2-noxpm-dev build-essential git python-software-properties python make |
第二步: 安装Java开发环境,至少是Java8
1 | yum install java-1.8.0-openjdk |
第三步: 安装Tomcat用于部署服务
1 | yum install tomcat |
使用vim,在/usr/share/tomcat/conf/tomcat.conf最后一行加入如下内容,提高运行内存
1 | JAVA_OPTS="-Xms512m -Xmx2g -XX:+CMSClassUnloadingEnabled -XX:+CMSPermGenSweepingEnabled -XX:+UseConcMarkSweepGC" |
假如基因组有超过1000的scaffolds,且有40个人同时处理一个项目,可以用如下的参数
1 | JAVA_OPTS="-Xmx12288m -Xms8192m \ |
使用vim编辑/usr/share/tomcat/conf/server.xml, 找到Connector port所在行,将其中的8080修改成合适的端口号
1 | <Connector port="8080" protocol="HTTP/1.1" |
启动和停止Tomcat服务
1 | tomcat start |
第四步: 安装nodejs和yarn。nodejs的版本在6-12之间都是可行的,我们可以使用nvm管理nodejs。
1 | curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.3/install.sh | bash |
第五步: 下载并解压缩Apollo
1 | wget https://github.com/GMOD/Apollo/archive/2.5.0.zip |
第六步: 配置数据库。Apollo支持H2, Postgres, MySQL,对应三个不同的配置文件
- sample-h2-apollo-config.groovy
- sample-postgres-apollo-config.groovy
- sample-mysql-apollo-config.groovy
可以按照需要将对应的文件重命名为apollo-config.groovy。默认情况下使用H2作为数据库。
如果需要用MySQL,需要先为apollo建立账号并授权
1 | # Login to mysql e.g., |
接着复制模板
1 | cp sample-mysql-apollo-config.groovy apollo-config.groovy |
然后更改apollo-config.groovy 中的username和password,也就是apollo和THE_PASSWORD。
个人建议: 有限选择H2数据库。
第七步: 使用vim修改配置文件grails-app/conf/Config.groovy
common_data_directory: 用户上传数据的目录,需要设置一个所有人都有权限访问的目录,例如
1 | common_data_directory = "/opt/temporary/apollo_data" |
然后建立对应的文件夹并更改权限
1 | mkdir -p /opt/temporary/apollo_data |
第八步: 部署apollo。
虽然只需要运行./apollo deploy即可,但是由于网络原因,可能会出现如下的报错
1 | ERROR: Failed to download Chromium r672088! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOAD" env variable to skip download. |
因此,需要先运行如下代码,修改镜像
1 | npm config set puppeteer_download_host=https://npm.taobao.org/mirrors |
最终会在target目录下生成一个以war结尾的文件,例如apollo-2.5.0.war, 该文件需要用Tomcat进行部署。
1 | cp target/apollo-2.5.0.war /usr/share/tomcat/webapps/apollo.war |
复制之后需要等待一段时间,才能打开对应的网页服务器IP:端口/apollo,第一次登陆需要先注册账号(随意填写)。
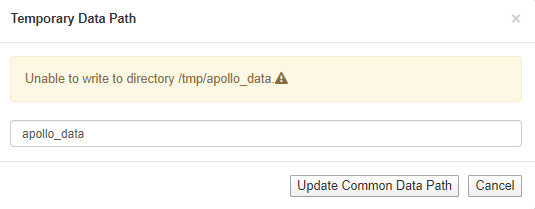
如果你发现出现了如下的警告,把其中的apollo_data改成/tmp即可
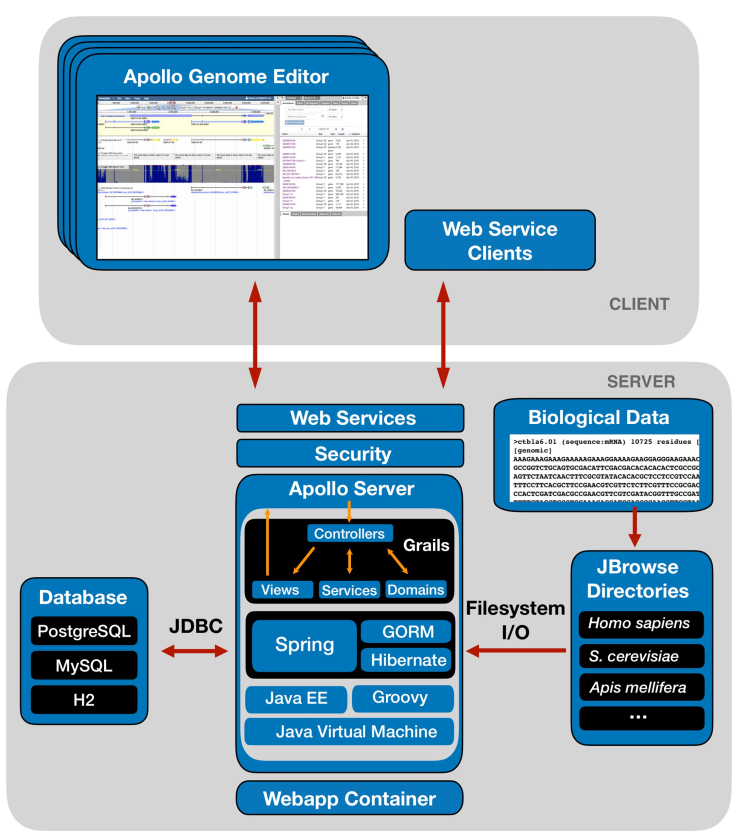
软件逻辑
软件分为用户端和服务器端。网页端基于Jbrowse,增加了Annotation Track,用于编辑新的注释信息,以及一个管理数据的侧边栏。
而服务端则分为三个部分,中间部分是基于Java开发的Apollo服务,用于和数据库端、文件系统交互。数据库端存放
Apollo服务端使用了Grails,一套用于快速Web应用开发的开源框架,它基于Groovy编程语言,并构建于Spring、Hibernate等开源框架之上,是一个高生产力一站式框架。数据库端目前主力是关系型数据库,例如PostgreSQL、MySQL和H2,将来还有Chado这种图数据库。文件系统端则是用户提供的各种生物学数据。
Citing Apollo: Dunn, N. A. et al. Apollo: Democratizing genome annotation. PLoS Comput. Biol. 15, e1006790 (2019)