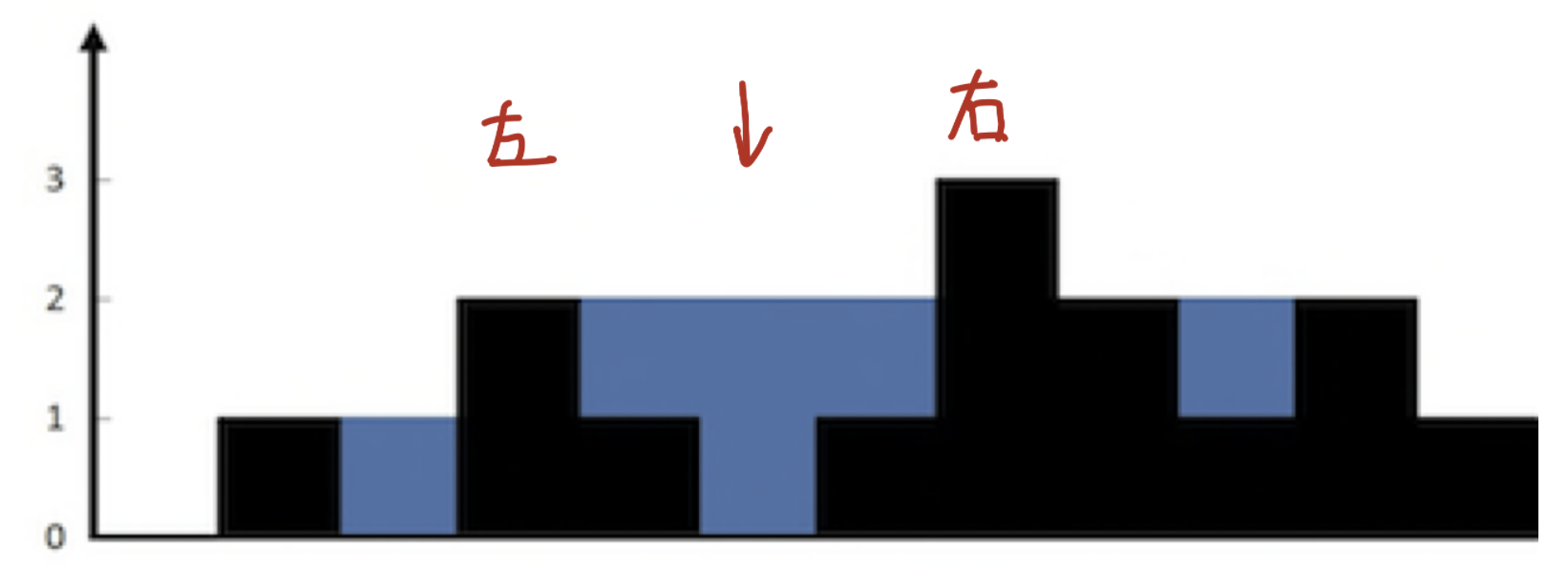
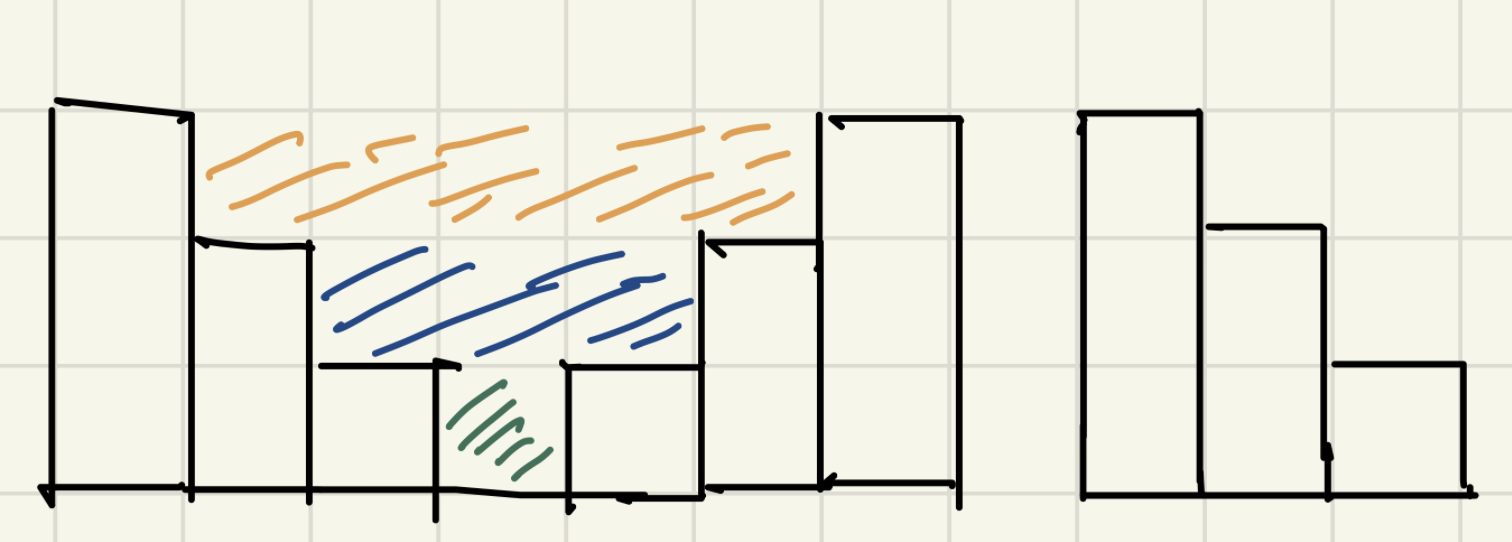
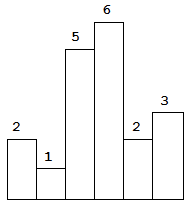
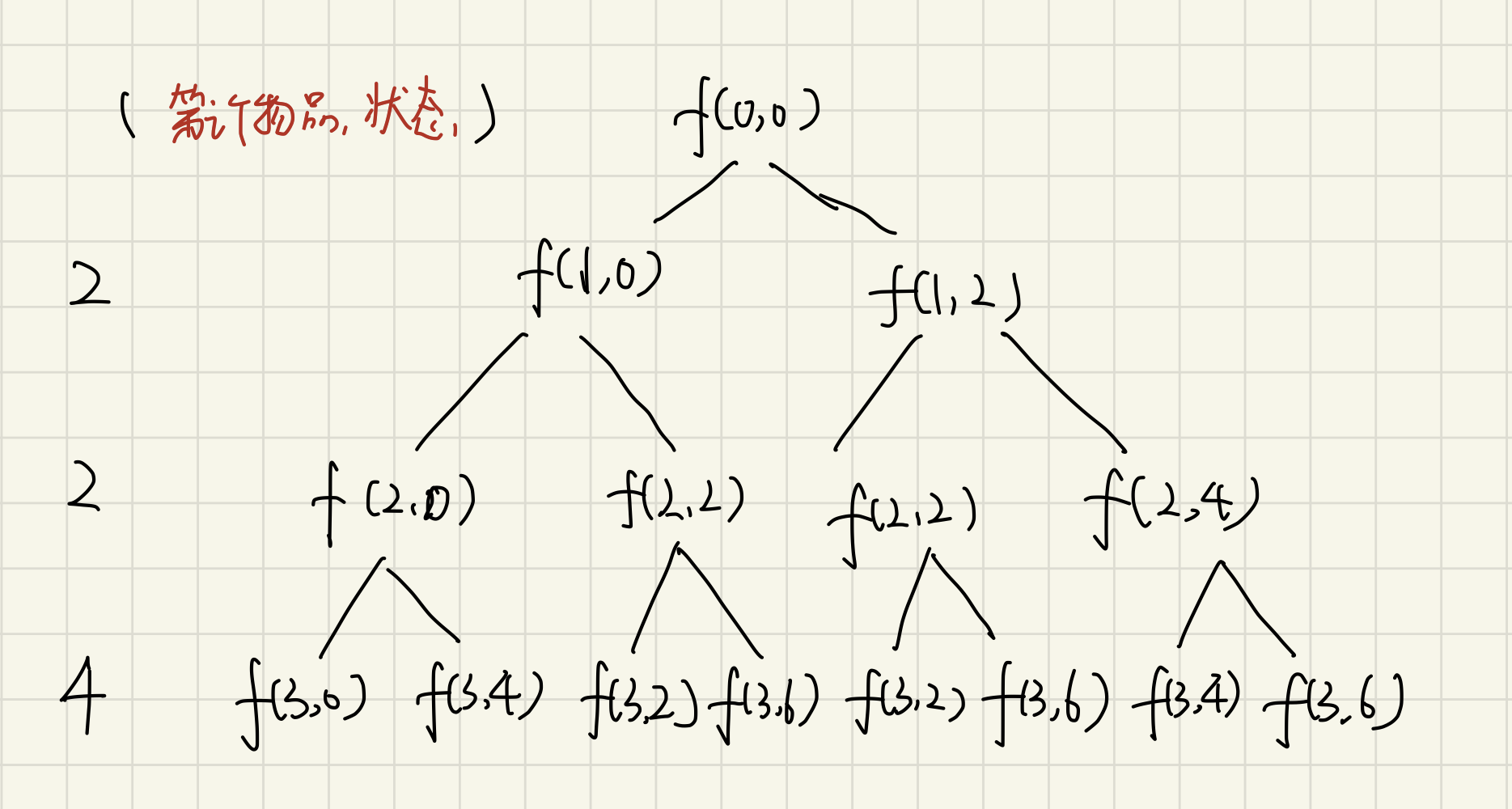
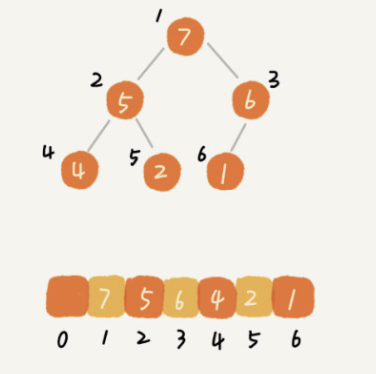
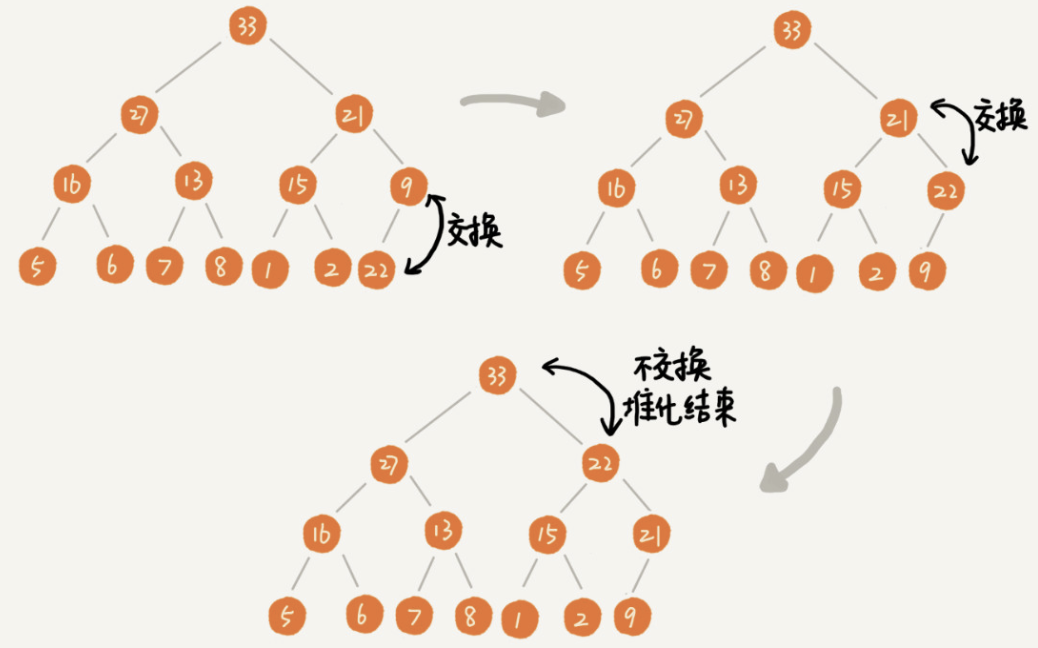
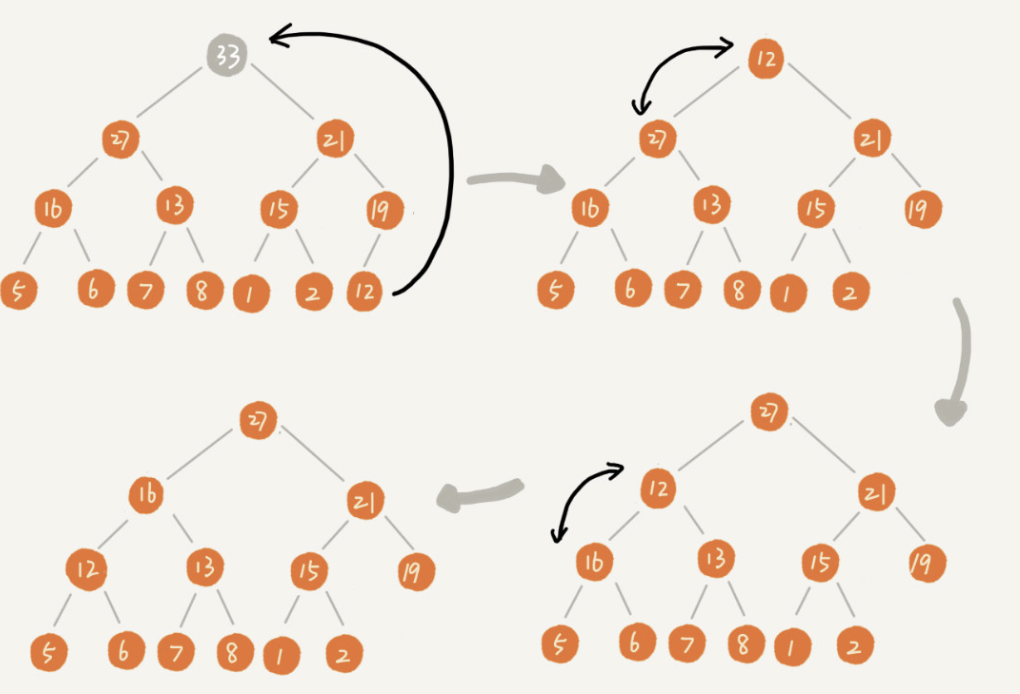
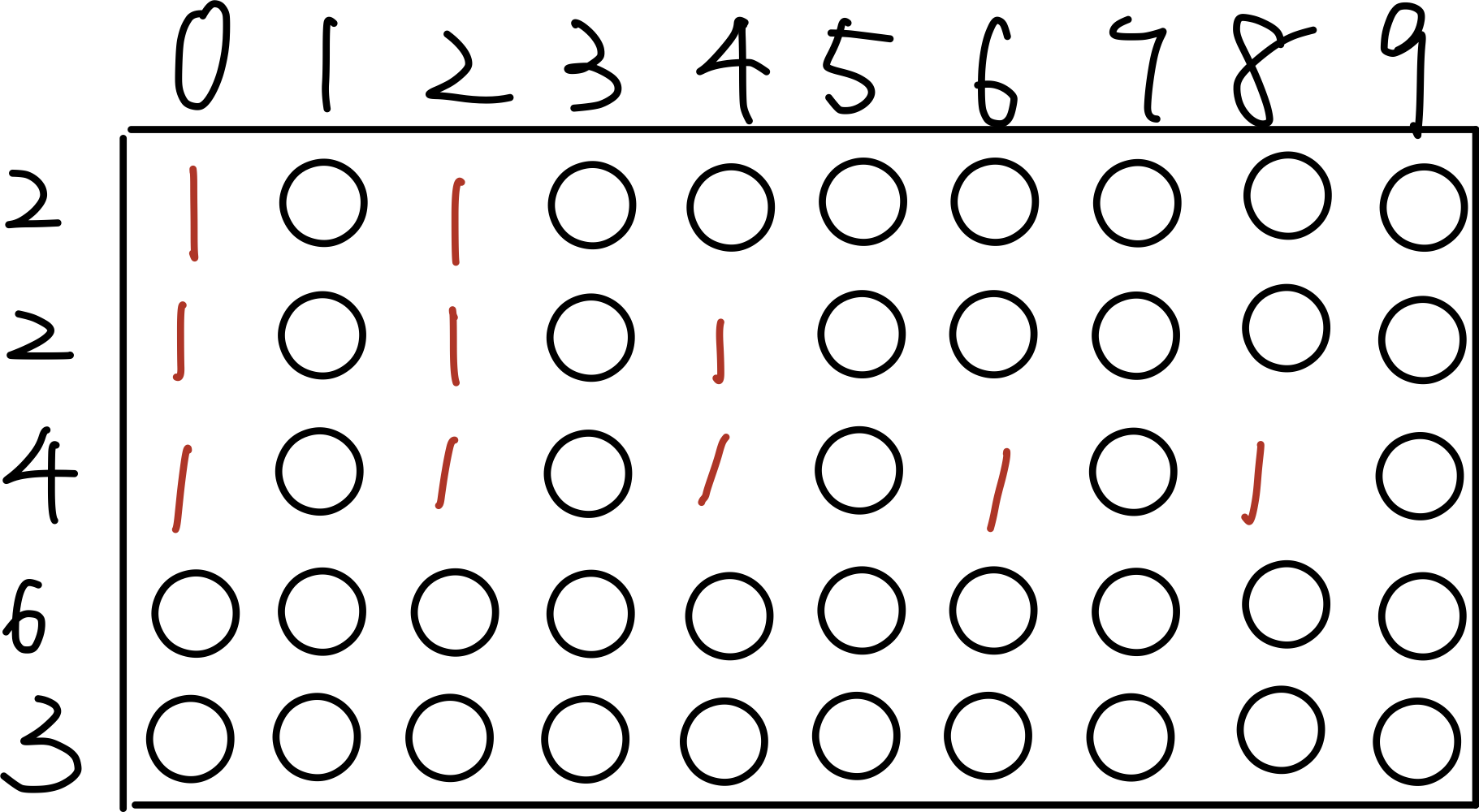classSolution { public: inttrap(vector<int>& height){ int ans = 0; stack<int> st; int current = 0; while( current < height.size()){ while( !st.empty() && height[current] > height[st.top()]){ //获取中间位置 int mid = st.top(); st.pop(); //获取左侧位置 if ( st.empty()) { break; } int left = st.top(); //左右间距 int distance = current - left - 1; //面积=高度差 x 距离 int bound_height = min(height[left], height[current] ) - height[mid]; ans += distance * bound_height; } st.push(current++); } return ans; } };
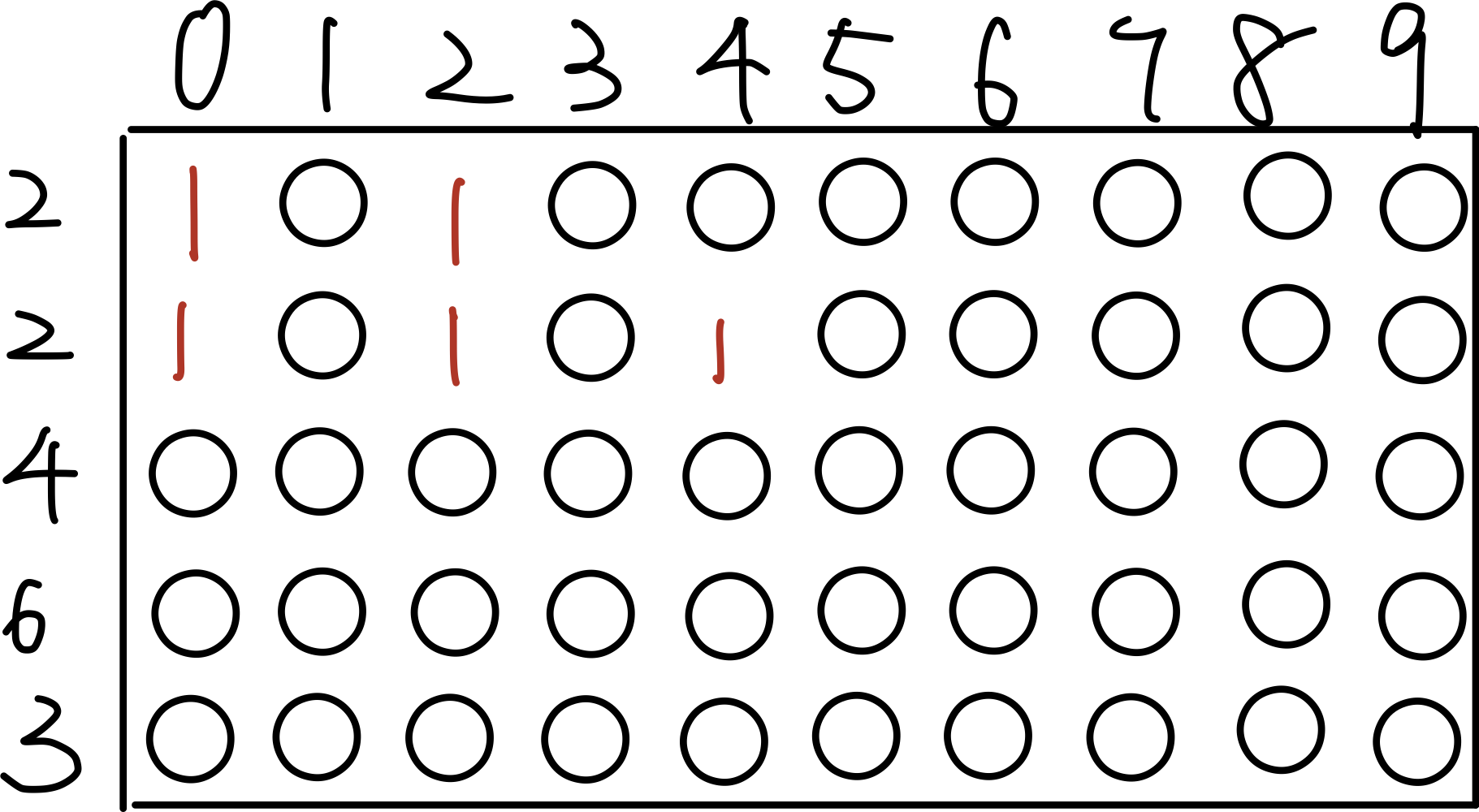
#include"klib/khash.h" KHASH_MAP_INIT_INT(m32, char) // instantiate structs and methods intmain() { int ret, is_missing; khint_t k; khash_t(m32) *h = kh_init(m32); // allocate a hash table k = kh_put(m32, h, 5, &ret); // insert a key to the hash table if (!ret) kh_del(m32, h, k); kh_value(h, k) = 10; // set the value k = kh_get(m32, h, 10); // query the hash table is_missing = (k == kh_end(h)); // test if the key is present k = kh_get(m32, h, 5); kh_del(m32, h, k); // remove a key-value pair for (k = kh_begin(h); k != kh_end(h); ++k) // traverse if (kh_exist(h, k)) // test if a bucket contains data kh_value(h, k) = 1; kh_destroy(m32, h); // deallocate the hash table return0; }
#include<stdio.h> #include"klib/khash.h" KHASH_MAP_INIT_INT(m32, char) // instantiate structs and methods intmain() { int ret, is_missing; khint_t k; khash_t(m32) *h = kh_init(m32); // allocate a hash table
int i = 0; for ( i = 0 ; i < 10 ; i++ ){ k = kh_put(m32, h, i, &ret); // insert a key to the hash table if (!ret) kh_del(m32, h, k); kh_value(h, k) = i * i; // set the value }
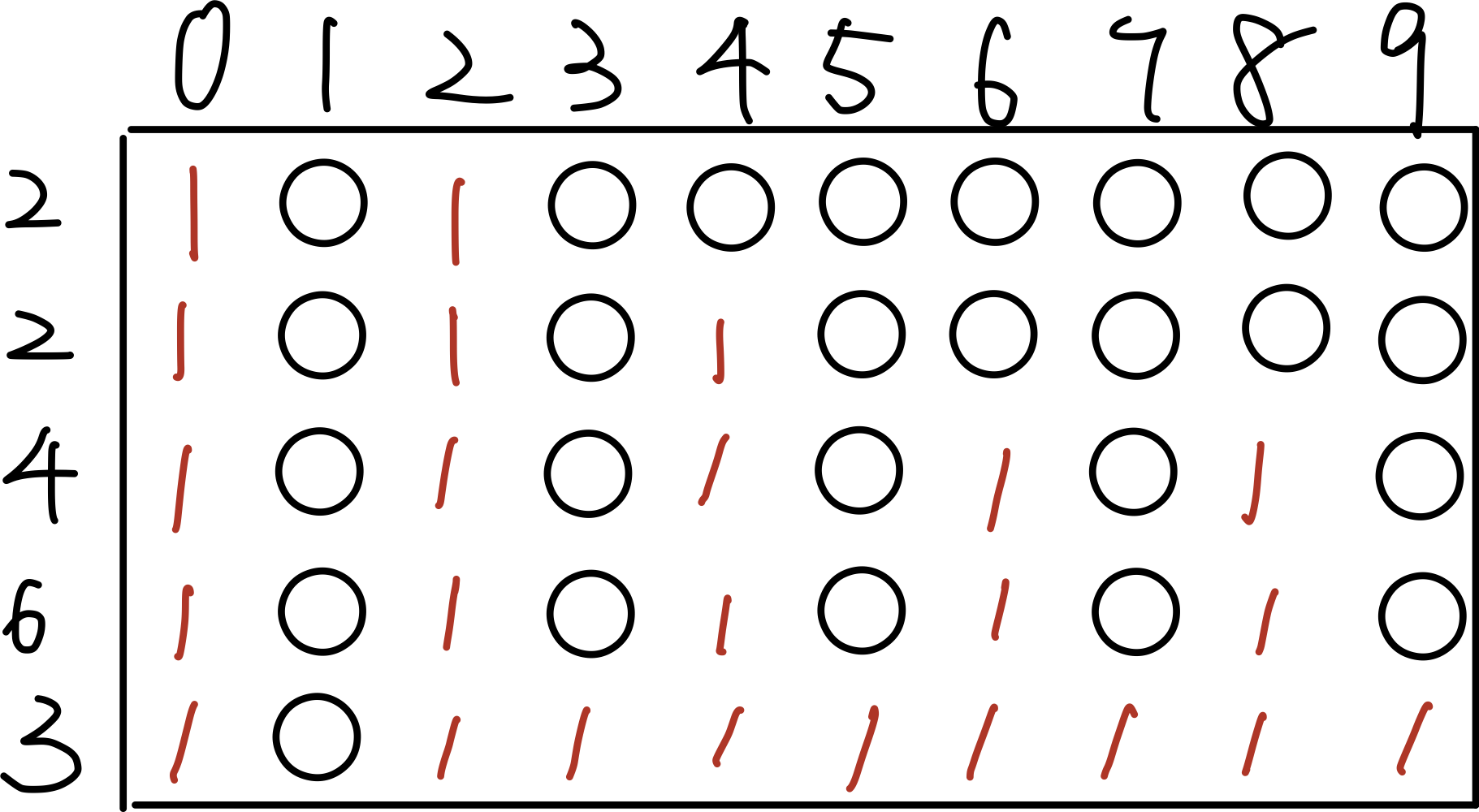
for (k = kh_begin(h); k != kh_end(h); ++k) // traverse if (kh_exist(h, k)) // test if a bucket contains data printf("%d\n", kh_value(h, k) ); kh_destroy(m32, h); // deallocate the hash table return0; }
gzopen can be used to read a file which is not in gzip format; in this case gzread will directly read from the file without decompression. When reading, this will be detected automatically by looking for the magic two-byte gzip header