第13章: ArchR的ChromVAR偏离富集分析
正如之前章节所提到的,TF motif富集可以帮助我们预测在我们感兴趣的细胞类型中哪些调控元件最为活跃。只不过这些富集既不是根据每个计算进行计算,也没有考虑到Tn5转座酶的序列偏好性。GreenLeaf Lab开发的 chromVARR包就是为了解决这些问题。chromVAR的设计目标就是要根据每个细胞的稀疏染色质开放数据来预测TF活跃富集情况。chromVAR的两个主要输出为
- “deviations”: deviation(偏离)是偏好校正值,它根据所有细胞或样本的预期开放度评估给定特征(例如motif)在每个细胞中的偏离程度。
- “z-score”: z-score也称之为”deviation score”, 是所有细胞中每个偏好纠正偏离值的z-score。偏离得分的绝对值和每个细胞的read深度相关。这是因为read越多,对于给定特征(例如motif)在每个细胞中相对于预期值存在的差异,你会更有把握,觉得它不可能是随机事情。
chromVAR的一个主要局限在于它是为早期scATAC-seq数据开发的,那个时候的实验只有上百个细胞。对于目前的数据规模,chromVAR很难将所有的cell-by-peak矩阵读取到内存中快速计算TF偏离。并且,当前的实验会输出成千上万个细胞,产生的cell-by-peak矩阵很难加载到内存中。于是,即便是中等大小数据(50,000个细胞),它的运行速度和内存占用都会急剧增加。
为了规避这些局限,ArchR通过分析独立的分析样本的每个子表达矩阵来实现相同的chromVAR分析流程。
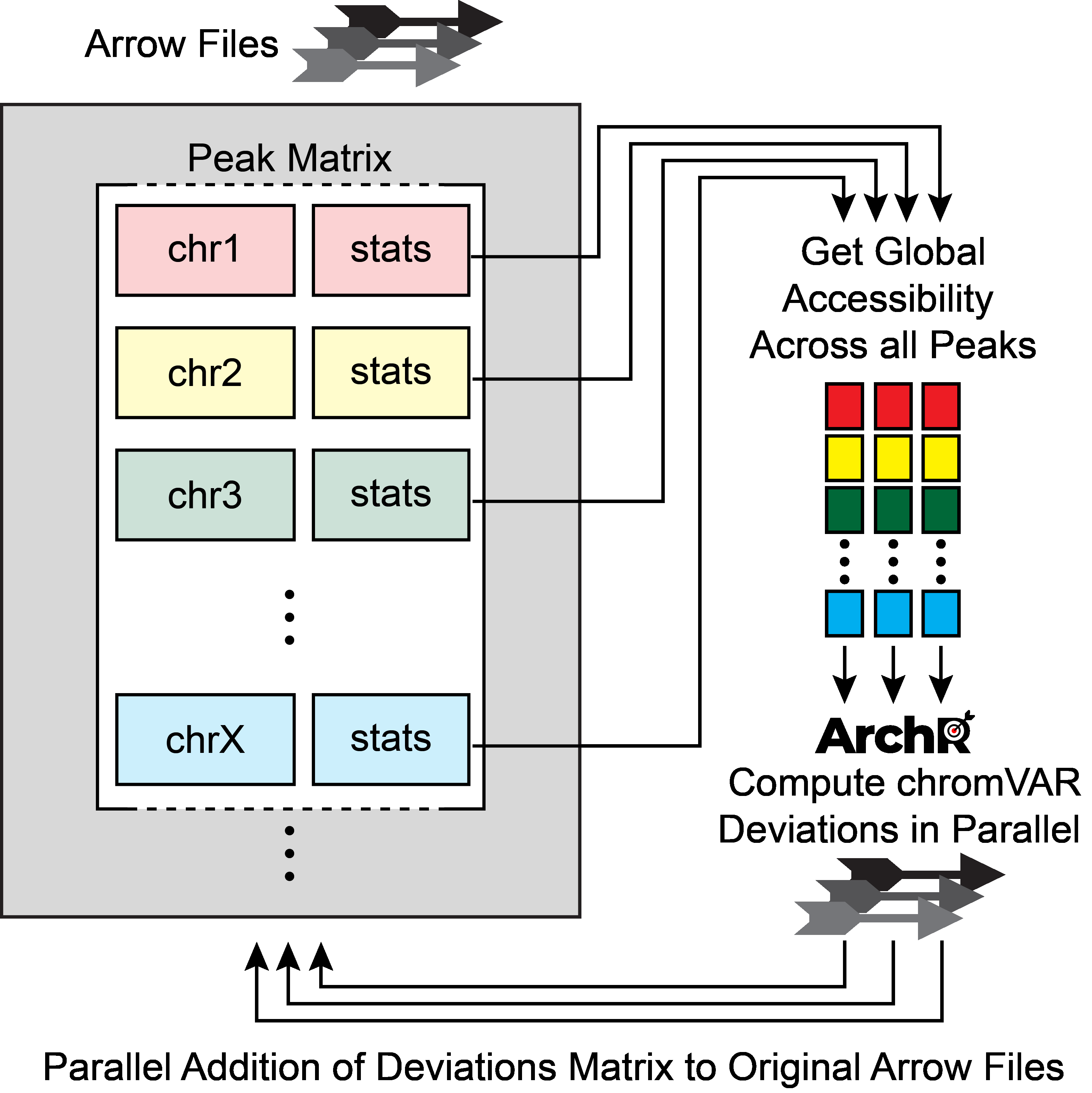
首先,ArchR读取每个子样本中所有细胞的全局开放性。然后,对于每个peak,ArchR根据GC含量和开放性确定一组背景peak。其次,对于每个样本,ArchR单独使用chromVAR根据背景peak集和全局开放性计算偏好校正后的离值。这种计算方式每次只会加载5,000-10,000细胞到内存中,因此降低了内存消耗。最终,我们能够在大规模数据中应用chromVAR并提升了运行性能。
13.1 Motif偏离
首先,我们要确保我们已经在ArchRProject中添加了motif注释
1
2
3
| if("Motif" %ni% names(projHeme5@peakAnnotation)){
projHeme5 <- addMotifAnnotations(ArchRProj = projHeme5, motifSet = "cisbp", name = "Motif")
}
|
此外,我们还需要添加一组背景peak用于计算偏离。背景peak通过chromVAR::getBackgroundPeaks()函数进行选择,该函数根据根据GC含量相似性和样本中的fragment数计算马氏距离然后对peak进行抽样。
1
| projHeme5 <- addBgdPeaks(projHeme5)
|
接下来,就可以使用addDeviatonMatrix()函数根据所有的motif注释计算每个细胞的偏离值。该函数有一个可选参数matrixName,用于定义该偏离值矩阵在Arrow文件里的名字。在下面的例子,函数会以”peakAnnotation”里设置的参数为基础,额外在后面添加字符串”Matrix”,因此下面函数运行结束后会为每个Arrow文件都创建了一个”MotifMatrix”的偏离值矩阵
1
2
3
4
5
| projHeme5 <- addDeviationsMatrix(
ArchRProj = projHeme5,
peakAnnotation = "Motif",
force = TRUE
)
|
我们用getVarDeviations()函数提取这些偏离值矩阵。假如我们需要它返回一个ggplot对象,那么只需要设置plot=TRUE即可,函数会返回一个DataFrame对象。函数运行后,会默认展示该DataFrame对象的前几行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| plotVarDev <- getVarDeviations(projHeme5, name = "MotifMatrix", plot = TRUE)
|
从上面DataFrame的输出信息中,你会发现MotifMatrix的seqnames并不是chromosome(染色体名)。通常而言,TileMatrix, PeakMatrix, GeneScoreMatrix,我们都是在seqnames中记录染色体信息。MotifMatrix并没有任何对应的位置信息,而是会在相同的矩阵里记录chromVAR输出的”devations”和”z-scores”信息,即deviations和z。如果你后续想在getMarkerFeatures()这类函数中使用MotifMatrix(Sparse.Assays.Matrix类)的话,那么这些信息就非常重要了。在这类操作中,ArchR会希望你从MotifMatrix提取其中一个seqnames(例如,选择z-scores或deviations执行计算)
我们先绘制这些偏离值
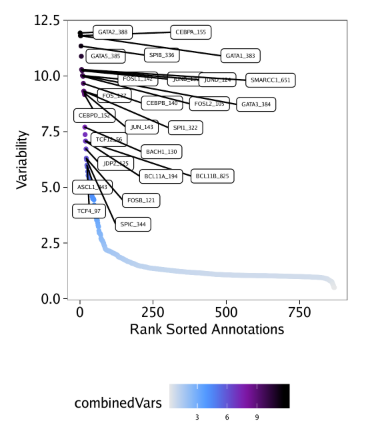
plotFDF()函数能够以可编辑的矢量版本保存图片。
1
| plotPDF(plotVarDev, name = "Variable-Motif-Deviation-Scores", width = 5, height = 5, ArchRProj = projHeme5, addDOC = FALSE)
|
假如我们想提取部分motif用于下游分析,那该怎么做呢?这就需要用到getFeatures()函数。下面的paste(motifs, collapse="|")语句会以”逻辑或”连接所有motifs里的值,用于选择给定的motif。
1
2
3
4
5
6
7
8
| motifs <- c("GATA1", "CEBPA", "EBF1", "IRF4", "TBX21", "PAX5")
markerMotifs <- getFeatures(projHeme5, select = paste(motifs, collapse="|"), useMatrix = "MotifMatrix")
markerMotifs
|
正如之前所提到的,MotifMatrix的seqnames包含z-scores(z:)和deviations(deviations:)。为了只提取对应特征的z-scores, 我们需要用到grep。此外,在之前的选择中由于”EBF1”会匹配到”SREBF1”,而后者并不是我们所需要的,因此我们还需要一步过滤。ArchR提供了%ni表达式,它是R提供的%ni%的反义词,表示反向选择。
1
2
3
| markerMotifs <- grep("z:", markerMotifs, value = TRUE)
markerMotifs <- markerMotifs[markerMotifs %ni% "z:SREBF1_22"]
markerMotifs
|
既然,我们已经有了我们感兴趣的特征,我们可以为每个cluster绘制chromVAR偏离得分。注,我们提供的是之前基因得分分析里计算的推断权重。考虑到scATAC-seq数据的稀疏性,推断权重利用邻近细胞对信号进行平滑处理。
1
2
3
4
5
6
| p <- plotGroups(ArchRProj = projHeme5,
groupBy = "Clusters2",
colorBy = "MotifMatrix",
name = markerMotifs,
imputeWeights = getImputeWeights(projHeme5)
)
|
我们使用cowplot将不同的moitfs的分布组合在一张图中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| p2 <- lapply(seq_along(p), function(x){
if(x != 1){
p[[x]] + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6) +
theme(plot.margin = unit(c(0.1, 0.1, 0.1, 0.1), "cm")) +
theme(
axis.text.y=element_blank(),
axis.ticks.y=element_blank(),
axis.title.y=element_blank()
) + ylab("")
}else{
p[[x]] + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6) +
theme(plot.margin = unit(c(0.1, 0.1, 0.1, 0.1), "cm")) +
theme(
axis.ticks.y=element_blank(),
axis.title.y=element_blank()
) + ylab("")
}
})
do.call(cowplot::plot_grid, c(list(nrow = 1, rel_widths = c(2, rep(1, length(p2) - 1))),p2))
|
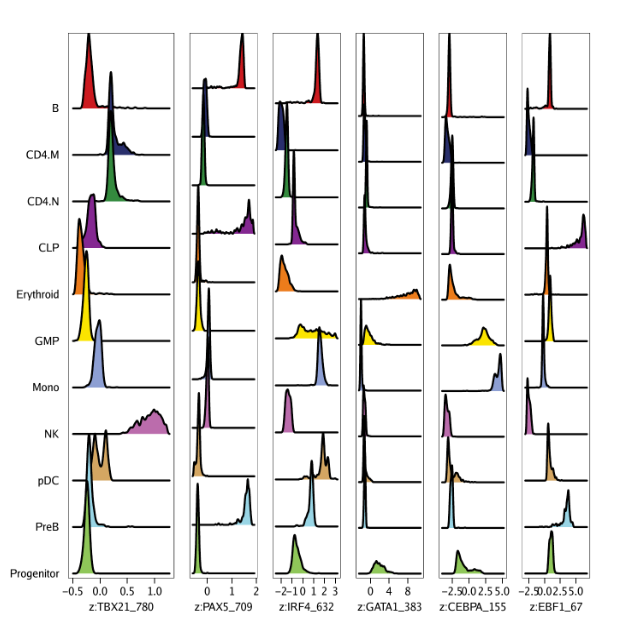
plotFDF()函数能够以可编辑的矢量版本保存图片。
1
| plotPDF(p, name = "Plot-Groups-Deviations-w-Imputation", width = 5, height = 5, ArchRProj = projHeme5, addDOC = FALSE)
|
除了检查z-scores的分布,我们也可以和之前展示基因得分一样将z-scores在UMAP嵌入图中进行展示
1
2
3
4
5
6
7
| p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "MotifMatrix",
name = sort(markerMotifs),
embedding = "UMAP",
imputeWeights = getImputeWeights(projHeme5)
)
|
我们可以使用cowplot将motif UMAP放在一张图上展示
1
2
3
4
5
6
7
8
9
10
11
12
| p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 3),p2))
|
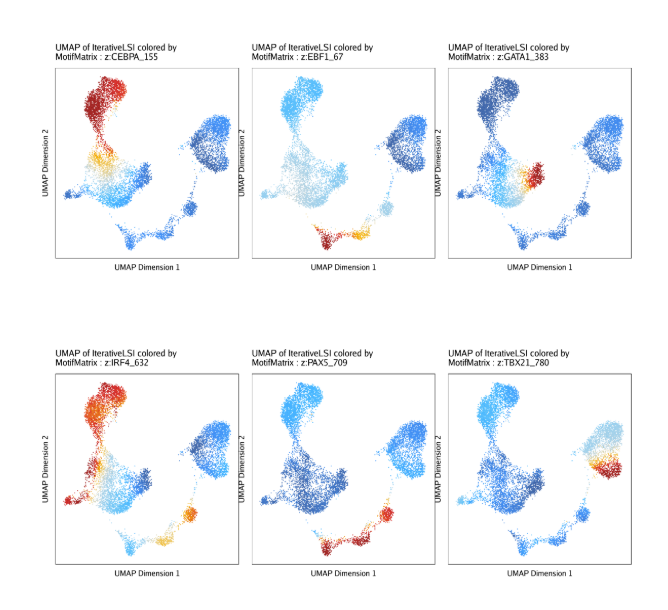
为了比较TF deviation z-scores和根据对应TF基因的基因得分推断的基因表达量,我们可以把这两者画在同一个UMAP中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| markerRNA <- getFeatures(projHeme5, select = paste(motifs, collapse="|"), useMatrix = "GeneScoreMatrix")
markerRNA <- markerRNA[markerRNA %ni% c("SREBF1","CEBPA-DT")]
p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "GeneScoreMatrix",
name = sort(markerRNA),
embedding = "UMAP",
imputeWeights = getImputeWeights(projHeme5)
)
p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 3),p2))
|
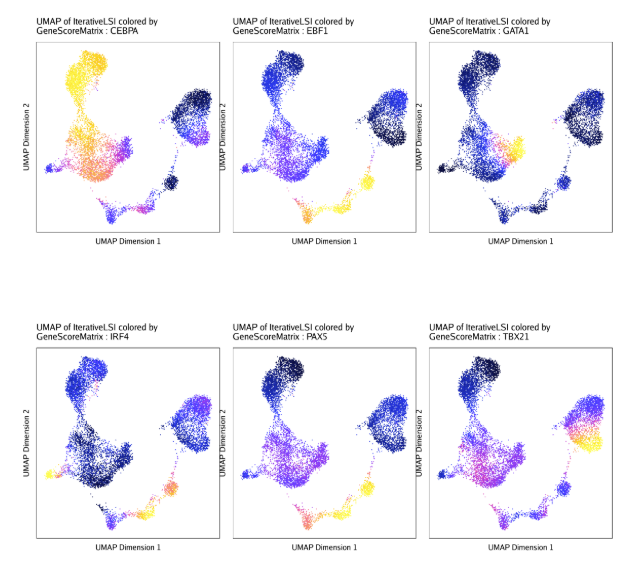
同样的,我们之前将对应的scRNA-seq数据和scATAC-seq数据进行了关联,我们也可以在UMAP图上绘制每个TF对应的基因表达量.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| markerRNA <- getFeatures(projHeme5, select = paste(motifs, collapse="|"), useMatrix = "GeneIntegrationMatrix")
markerRNA <- markerRNA[markerRNA %ni% c("SREBF1","CEBPA-DT")]
p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "GeneIntegrationMatrix",
name = sort(markerRNA),
embedding = "UMAP",
continuousSet = "blueYellow",
imputeWeights = getImputeWeights(projHeme5)
)
p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 3),p2))
|
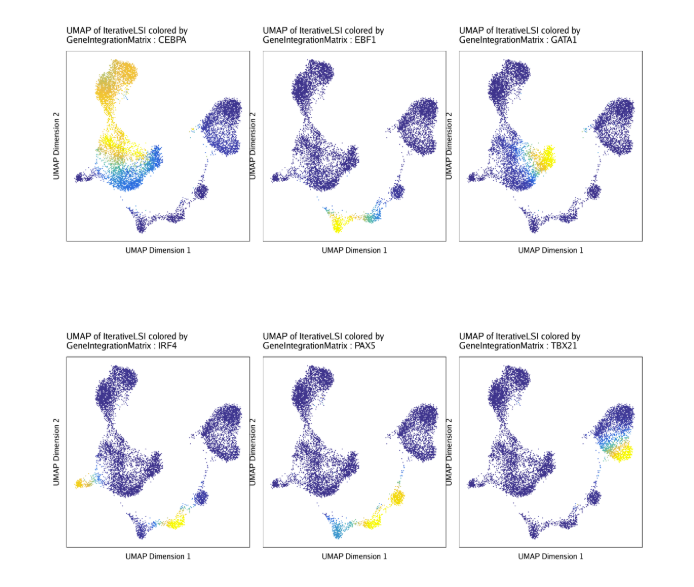
13.2 ArchR和自定义偏离
在Peak Annotation Enrichment一章中,我们介绍了如何根据任意的基因组区域创建peak注释。这包括 1)ArchR支持的区域集,例如来自于ENCODE人工审核过的TF结合位点和混合ATAC-seq;2) 用户自定义的区域集。如果你没有阅读该章节,我们建议先去阅读一遍,这样能很好的理解peak注释是如何工作的。
这些peak注释能和motif一样用于计算偏离。这里,我们提供了一些例子关于这类分析,由于代码和之前motif分析类似,因此我们不会对每一步的代码做详细的解释。一旦你在Arrow文件中创建了偏离矩阵,其他都是相同的。
13.2.1 Encode TFBS
同样,我们要确保我们已经在ArchRProject中添加了”Encode TFBS”注释矩阵
1
2
3
| if("EncodeTFBS" %ni% names(projHeme5@peakAnnotation)){
projHeme5 <- addArchRAnnotations(ArchRProj = projHeme5, collection = "EncodeTFBS")
}
|
接着,我们创建偏离矩阵,以”Encode TFBS”作为peakAnnotation参数的输入
1
2
3
4
5
| projHeme5 <- addDeviationsMatrix(
ArchRProj = projHeme5,
peakAnnotation = "EncodeTFBS",
force = TRUE
)
|
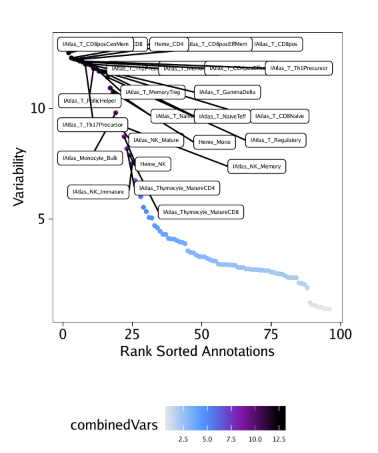
我们就可以绘制排序deviations的点图
1
2
| plotVarDev <- getVarDeviations(projHeme5, plot = TRUE, name = "EncodeTFBSMatrix")
plotVarDev
|
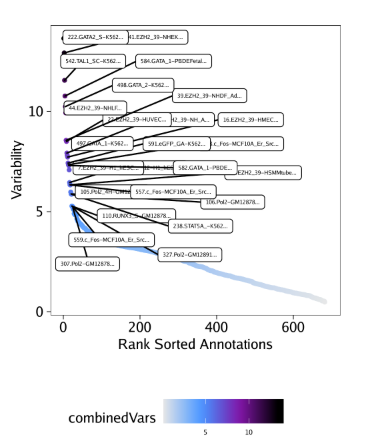
保存为PDF
1
| plotPDF(plotVarDev, name = "Variable-EncodeTFBS-Deviation-Scores", width = 5, height = 5, ArchRProj = projHeme5, addDOC = FALSE)
|
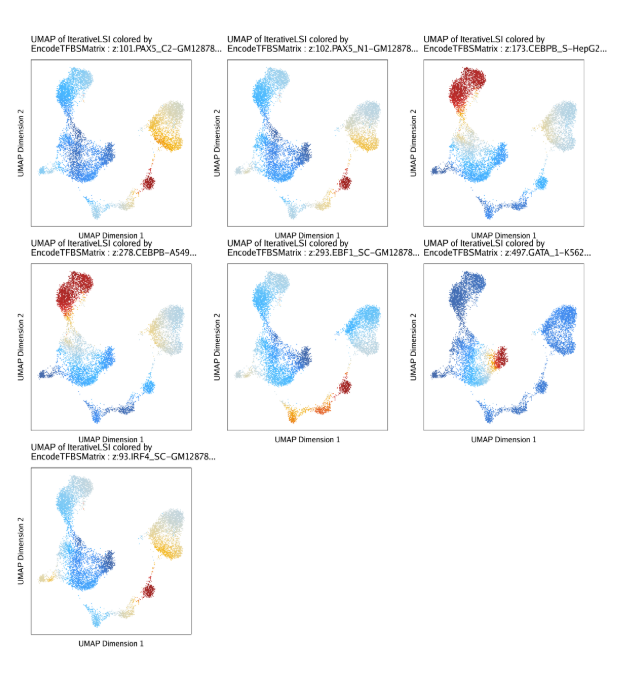
或者,我们可以提取和特定motif相关的TF结合位点,然后在UMAP嵌入中绘制每个细胞的deviation z-scores。代码和上一节类似。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| tfs <- c("GATA_1", "CEBPB", "EBF1", "IRF4", "TBX21", "PAX5")
markerTFs <- getFeatures(projHeme5, select = paste(tfs, collapse="|"), useMatrix = "EncodeTFBSMatrix")
markerTFs <- sort(grep("z:", markerTFs, value = TRUE))
TFnames <- stringr::str_split(stringr::str_split(markerTFs, pattern = "\\.", simplify=TRUE)[,2], pattern = "-", simplify = TRUE)[,1]
markerTFs <- markerTFs[!duplicated(TFnames)]
p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "EncodeTFBSMatrix",
name = markerTFs,
embedding = "UMAP",
imputeWeights = getImputeWeights(projHeme5)
)
p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 3),p2))
|
13.2.2 混池ATAC-seq
类似的,我们可以使用ArchR审核过的混池ATAC-seq peak集来计算motif偏离。下面的代码用来增加ATAC的注释
1
2
3
| if("ATAC" %ni% names(projHeme5@peakAnnotation)){
projHeme5 <- addArchRAnnotations(ArchRProj = projHeme5, collection = "ATAC")
}
|
接着创建偏离矩阵
1
2
3
4
5
| projHeme5 <- addDeviationsMatrix(
ArchRProj = projHeme5,
peakAnnotation = "ATAC",
force = TRUE
)
|
然后画图
1
2
| plotVarDev <- getVarDeviations(projHeme5, plot = TRUE, name = "ATACMatrix")
plotVarDev
|
保存为PDF
1
| plotPDF(plotVarDev, name = "Variable-ATAC-Deviation-Scores", width = 5, height = 5, ArchRProj = projHeme5, addDOC = FALSE)
|
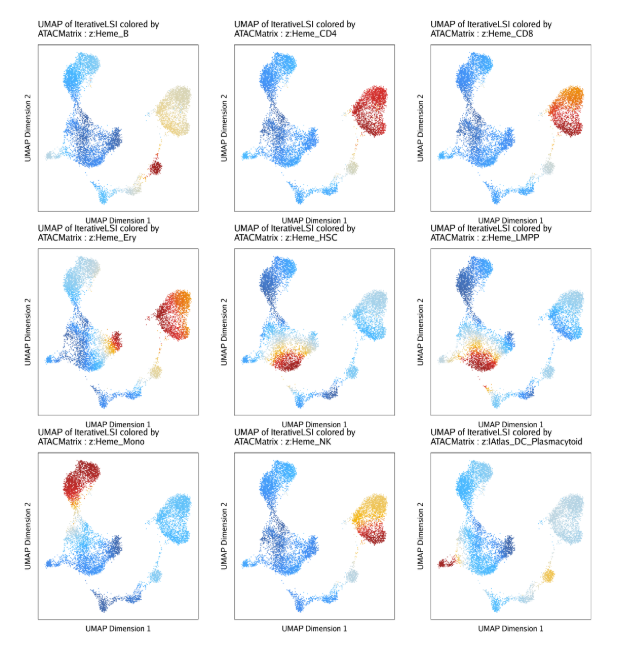
另外,我们还可以在UMAP图上绘制deviation z-scores和每个细胞的peak集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ATACPeaks <- c("Heme_HSC", "Heme_LMPP", "Heme_Ery", "Heme_Mono", "Heme_CD4", "Heme_CD8", "Heme_B", "Heme_NK", "IAtlas_DC_Plasmacytoid")
markerATAC <- getFeatures(projHeme5, select = paste(ATACPeaks, collapse="|"), useMatrix = "ATACMatrix")
markerATAC <- sort(grep("z:", markerATAC, value = TRUE))
p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "ATACMatrix",
name = markerATAC,
embedding = "UMAP",
imputeWeights = getImputeWeights(projHeme5)
)
p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 3),p2))
|
13.2.3 自定义偏离
除了使用ArchR审核过的区域集,我们也能够提供自己区域集作为peak注释。这些注释和ArchR审核过的注释使用方法相同。
首先,如果你没有在之前的章节中创建”EncodePeaks”, 我们需要先下载一些ENCODE peak,然后调用addPeakAnnotations()函数
1
2
3
4
5
6
7
8
9
| EncodePeaks <- c(
Encode_K562_GATA1 = "https://www.encodeproject.org/files/ENCFF632NQI/@@download/ENCFF632NQI.bed.gz",
Encode_GM12878_CEBPB = "https://www.encodeproject.org/files/ENCFF761MGJ/@@download/ENCFF761MGJ.bed.gz",
Encode_K562_Ebf1 = "https://www.encodeproject.org/files/ENCFF868VSY/@@download/ENCFF868VSY.bed.gz",
Encode_K562_Pax5 = "https://www.encodeproject.org/files/ENCFF339KUO/@@download/ENCFF339KUO.bed.gz"
)
if("ChIP" %ni% names(projHeme5@peakAnnotation)){
projHeme5 <- addPeakAnnotations(ArchRProj = projHeme5, regions = EncodePeaks, name = "ChIP")
}
|
接着,我们从这些peak注释中创建偏离值矩阵
1
2
3
4
5
| projHeme5 <- addDeviationsMatrix(
ArchRProj = projHeme5,
peakAnnotation = "ChIP",
force = TRUE
)
|
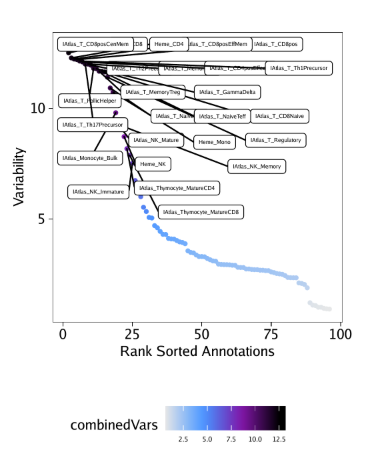
后续的分析就和之前的一模一样
1
2
| plotVarDev <- getVarDeviations(projHeme5, plot = TRUE, name = "ChIPMatrix")
plotVarDev
|
保存PDF
1
| plotPDF(plotVarDev, name = "Variable-ChIP-Deviation-Scores", width = 5, height = 5, ArchRProj = projHeme5, addDOC = FALSE)
|
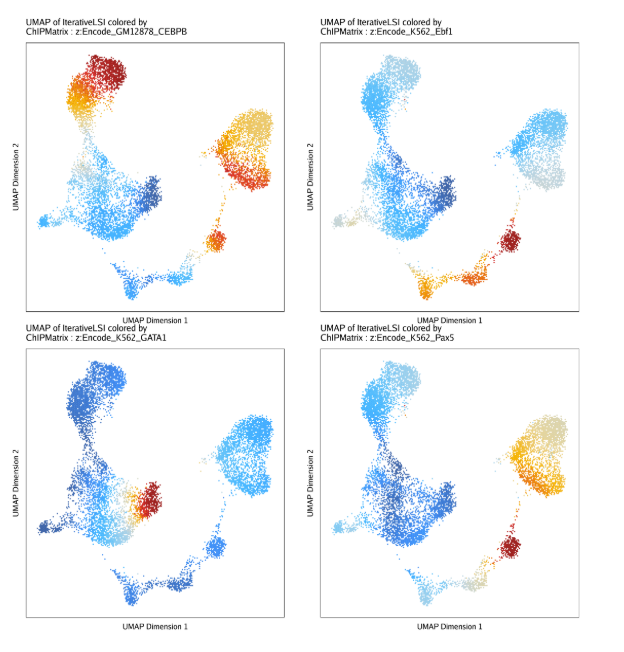
在UMAP上同时展示结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| markerChIP <- getFeatures(projHeme5, useMatrix = "ChIPMatrix")
markerChIP <- sort(grep("z:", markerChIP, value = TRUE))
p <- plotEmbedding(
ArchRProj = projHeme5,
colorBy = "ChIPMatrix",
name = markerChIP,
embedding = "UMAP",
imputeWeights = getImputeWeights(projHeme5)
)
p2 <- lapply(p, function(x){
x + guides(color = FALSE, fill = FALSE) +
theme_ArchR(baseSize = 6.5) +
theme(plot.margin = unit(c(0, 0, 0, 0), "cm")) +
theme(
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank()
)
})
do.call(cowplot::plot_grid, c(list(ncol = 2),p2))
|