谈论到直系同源基因分析的时候,大部分教程都是介绍OrthoMCL,这是2003年发表的一个工具,目前的引用次数已经达到了3000多,但这个软件似乎在2013年之后就不在更新,而且安装时还需要用到MySQL(GitHub上有人尝试从MySQL转到sqlite)。
而OrthoFinder则是2015年出现的软件,目前已有400多引用。该软件持续更新,安装更加友好,因此我决定使用它来做直系同源基因的相关分析。
OrthoFinder能做什么?
OrthoFinder: solving fundamental biases in whole genome comparisons dramatically improves orthogroup inference accuracy提到,它的优点就是比其他的直系同源基因组的推断软件准确,并且速度还快。
此外他还能分析所提供物种的系统发育树,将基因树中的基因重复事件映射到物种树的分支上,还提供了一些比较基因组学中的统计结果。
OrthoFinder的分析过程
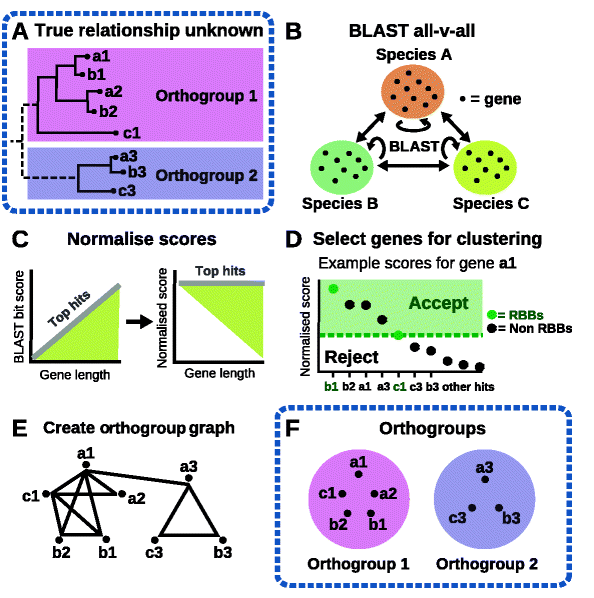
OrthoFinder的分析过程分为如下几步:
- BLAST all-vs-all搜索。使用BLASTP以evalue=10e-3进行搜索,寻找潜在的同源基因。(除了BLAST, 还可以选择DIAMOND和MMSeq2)
- 基于基因长度和系统发育距离对BLAST bit得分进行标准化。
- 使用RBNHs确定同源组序列性相似度的阈值
- 构建直系同源组图(orthogroup graph),用作MCL的输入
- 使用MCL对基因进行聚类,划分直系同源组
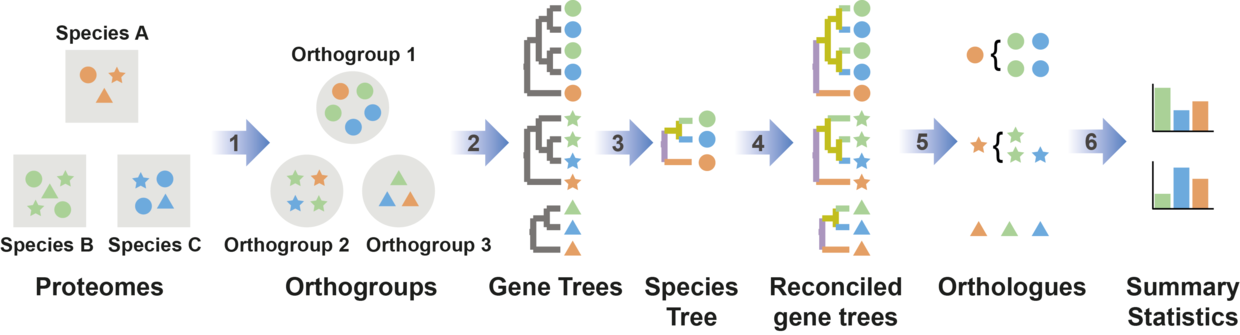
OrthoFinder2在OrthoFinder的基础上增加了物种系统发育树的构建,流程如下
- 为每个直系同源组构建基因系统发育树
- 使用STAG算法从无根基因树上构建无根物种树
- 使用STRIDE算法构建有根物种树
- 有根物种树进一步辅助构建有根基因树
基于Duplication-Loss-Coalescent 模型,有根基因树可以用来推断物种形成和基因复制事件,最后记录在统计信息中。
软件使用
在解压缩的OrthoFinder文件目录下(安装见最后)有一个 ExampleData, 里面就是用于测试的数据集。
1 | orthofinder -f ExampleData -S mmseqs |
OrthoFinder的基本使用就是如此简单,而且最终效果也基本符合需求。
如果你想根据多序列联配(MSA)结果按照极大似然法构建系统发育树,那么你需要加上-M msa。这样结果会更加准确,但是代价就是运行时间会更久,这是因为OrthoFinder要做10,000 - 20,000个基因树的推断。
OrthoFinder默认用mafft进行多序列联配,用fasttree进行进化树推断。多序列联配软件还支持muscle, 进化树推断软件还支持iqtree, raxml-ng, raxml。例如参数可以设置为-M msa -A mafft -T raxml.
并行化参数: -t参数指定序列搜索时的线程数,-a指的是序列搜索后分析的CPU数。
软件细节
OrthoFinder提供了config.json可以调整不同软件的参数,如下是BLASTP。

OrthoFinder默认使用DendroBLAST发育树,也就是根据序列相似度推断进化关系。这是作者推荐的方法,在损失部分准确性的前提下提高了运算效率。当然你可以用-M msa从多序列比对的基础上进行基因树构建。如果你先用了默认的DendroBLAST,想测试下传统的MSA方法,那么也不需要重头运行,因为有一个-b参数可以在复用之前的比对结果。
在物种发育树的推断上,OrthoFinder使用STAG算法,利用所有进行构建系统发育树,而非单拷贝基因。此外当使用MSA方法进行系统发育树推断时,OrthoFinder为了保证有足够多的基因(大于100)用于分析,除了使用单拷贝基因外,还会挑选大部分是单拷贝基因的直系同源组。这些直系同源组的基因前后相连,用空缺字符表示缺失的基因,如果某一列存在多余50%的空缺字符,那么该列被剔除。最后基于用户指定的建树软件进行系统发育树构建。结果在”WorkingDirectory/SpeciesTree_unrooted.txt”
使用STRIDE算法从无根树中推断出有根树, 结果就是”SpeciesTree_rooted.txt”.
结果文件
运行结束后,会在ExampleData里多出一个文件夹,Results_Feb14, 其中Feb14是我运行的日期
直系同源组相关结果文件,将不同的直系同源基因进行分组
- Orthogroups.csv:用制表符分隔的文件,每一行是直系同源基因组对应的基因。
- Orthogroups.txt: 类似于Orthogroups.csv,只不过是OrhtoMCL的输出格式
- Orthogroups_UnassignedGenes.csv: 格式同Orthogroups.csv,只不过是物种特异性的基因
- Orthogroups.GeneCount.csv:格式同Orthogroups.csv, 只不过不再是基因名信息,而是以基因数。
直系同源相关文件,分析每个直系同源基因组里的直系同源基因之间关系,结果会在Orthologues_Feb14文件夹下,其中Feb14是日期
- Gene_Trees: 每个直系同源基因基因组里的基因树
- Recon_Gene_Trees:使用OrthoFinder duplication-loss coalescent 模型进行发育树推断
- Potential_Rooted_Species_Trees: 可能的有根物种树
- SpeciesTree_rooted.txt: 从所有包含STAG支持的直系同源组推断的STAG物种树
- SpeciesTree_rooted_node_labels.txt: 同上,只不过多了一个标签信息,用于解释基因重复数据。
比较基因组学的相关结果文件:
- Orthogroups_SpeciesOverlaps.csv: 不同物种间的同源基因的交集
- SingleCopyOrthogroups.txt: 单基因拷贝组的编号
- Statistics_Overall.csv:总体统计信息
- Statistics_PerSpecies.csv:分物种统计信息
STAG是一种从所有基因推测物种树的算法,不同于使用单拷贝的直系同源基因进行进化树构建。
一些重要概念:
- Species-specific orthogroup: 一个仅来源于一个物种的直系同源组
- Single-copy orthogroup: 在直系同源组中,每个物种里面只有一个基因。我们会用单拷贝直系同源组里的基因推断物种树以及其他数据分析。
- Unassigned gene: 无法和其他基因进行聚类的基因。
- G50和O50,指的是当你直系同源组按照基因数从大到小进行排列,然后累加,当加入某个组后,累计基因数大于50%的总基因数,那么所需要的直系同源组的数目就是O50,该组的基因树就是G50.
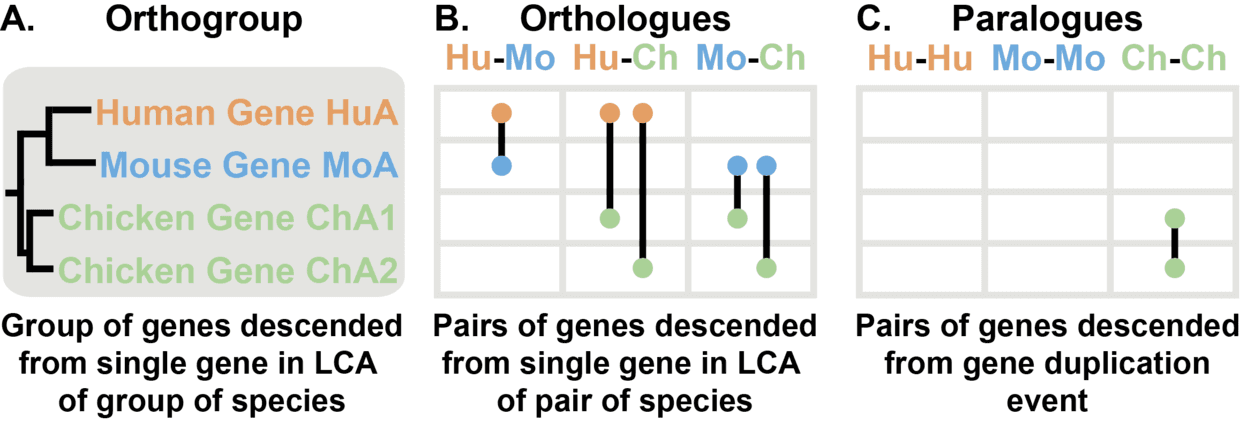
Orthogroups, Orthologs 和 Paralogs 这三个概念推荐看图理解。
如何安装?
最快的方法
OrthoFinder可以通过conda安装,建议为它新建一个虚拟环境
1 | conda create -n orthofinder orthofinder=2.2.7 |
如果你愿意折腾
你先得安装它的三个依赖工具: MCL, FastME, DIAMOND/MMseqs2/BLAST+
MCL有两种安装方式,最简单的就是用sudo apt-get install mcl, 但是对于大部分人可能没有root权限,因此这里用源代码编译。http://micans.org/mcl/
1 | wget https://www.micans.org/mcl/src/mcl-latest.tar.gz |
之后是MMseqs2, 一个蛋白搜索和聚类工具集,相关文章发表在NBT, NC上。GitHub地址为https://github.com/soedinglab/MMseqs2
1 | wget https://github.com/soedinglab/MMseqs2/releases/download/3-be8f6/MMseqs2-Linux-AVX2.tar.gz |
最后安装FastME, 这是一个基于距离的系统发育树推断软件。在http://www.atgc-montpellier.fr/fastme/binaries.php下载,上传到服务器
1 | tar xf fastme-2.1.5.tar.gz |
BLAST+可装可不装,推荐阅读这或许是我写的最全的BLAST教程
以上软件安装之后,都需要将其添加到环境变量中,才能被OrthoFinder调用。
之后在https://github.com/davidemms/OrthoFinder/releases 寻找最近的稳定版本下载到本地,例如OrthoFinder v2.2.7
1 | tar xzf OrthoFinder-2.2.7.tar.gz |